
Синхронная репликация БД: какая от неё польза? (Synchronous DBMS Replication: what is it good for)

Алексей Юрченко: Здравствуйте. Меня зовут Алексей Юрченко. Я представляю компанию "Codership". Это маленькая финская компания. Мы занимаемся разработкой универсальной репликационной библиотеки для синхронной репликации транзакционных приложений. Она не "завязана" ни на какую базу данных, и вообще ни на какое приложение.
За последние пару лет мы и наши клиенты накопили некий опыт использования синхронной репликации, которым я и собираюсь с вами поделиться в рамках этого доклада. Речь пойдет об использовании синхронной репликации в глобальных сетях, то есть между географически распределенными узлами (грубо говоря, в Интернете).
Традиционно считается, что синхронная репликация слишком медленная. Никто ее не использует. Для целей репликации в глобальных сетях синхронная репликация, как считается, вообще не применима. Я собираюсь показать, что это не совсем так. В некоторых случаях с помощью синхронной репликации можно серьезно ускорить доступ к данным.
Для начала хотел бы поинтересоваться. Кто из вас использует синхронную репликацию? Два человека. Скажите, какой тип синхронной репликации вы применяете?
Реплика из зала: Схема "ведущий-ведущий" (англ. master-master). Если база, то PostgreSQL.
Алексей Юрченко: Итак, этот специалист использует синхронную репликацию в PostgreSQL. А вы?
Реплика из зала: Тоже PostgreSQL, только по схеме "ведущий-ведомый" (англ. master-slave). Ведущий – на записи чтения, и ведомый в других случаях.
Алексей Юрченко: Полусинхронная репликация у вас реализована?
Реплика из зала: Да.
Алексей Юрченко: В начале стоит рассказать о том, что такое синхронная репликация, как мы ее понимаем.

Мы, конечно, все понимаем, что такое синхронная репликация. Но это понимание зачастую консервативно. Хотелось бы объяснить, откуда берутся представления о синхронной репликации как о медленной и неэффективной. Чтобы потом вам стало понятно, почему это не совсем так.
Мифы о синхронной репликации
Начнем с асинхронной репликации. Зачем нам вообще синхронная репликация, когда у нас есть асинхронная? Она замечательно работает.
Вот примерная схема того, как работает асинхронная репликация в приложении.
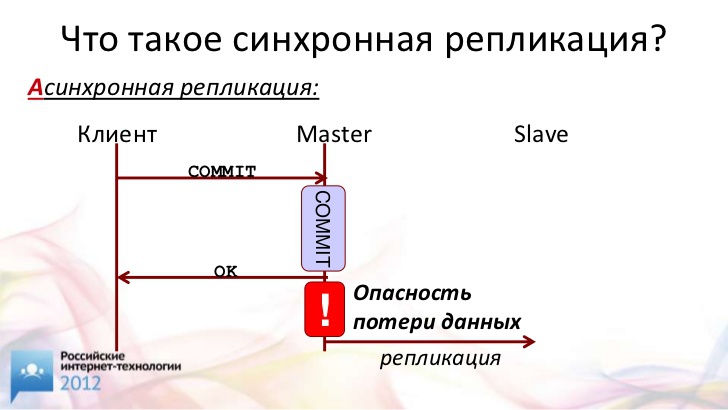
От клиента получаем "commit", коммитим транзакцию. Посылаем клиенту "ОК". А потом как-нибудь отсылаем данные на ведомый сервер. В этом месте наши данные могут быть потеряны, если ведущий вдруг "упал". Эти данные могут быть потеряны до восстановления ведущего сервера или навсегда. Если у вас "полетел" блок питания, если у вас не было батарейки в диске или произошла другая подобная вещь, части данных практически всегда приходится говорить "до свиданья".
Для ряда случаев это совершенно не принципиально. Если потеряется какой-нибудь комментарий на бесплатном форуме, то это никого не волнует. А вот в финансовых или телекоммуникационных приложениях потеря данных не должна происходить ни в коем случае. Единственное решение, которое мне известно (может быть, есть и другие) – это синхронная репликация.
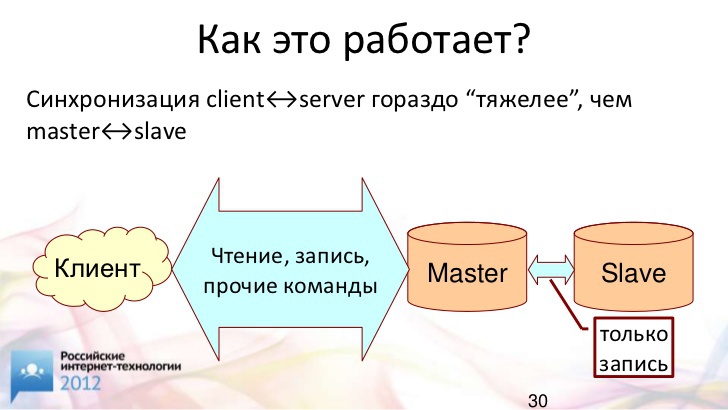
Что происходит при синхронной репликации?
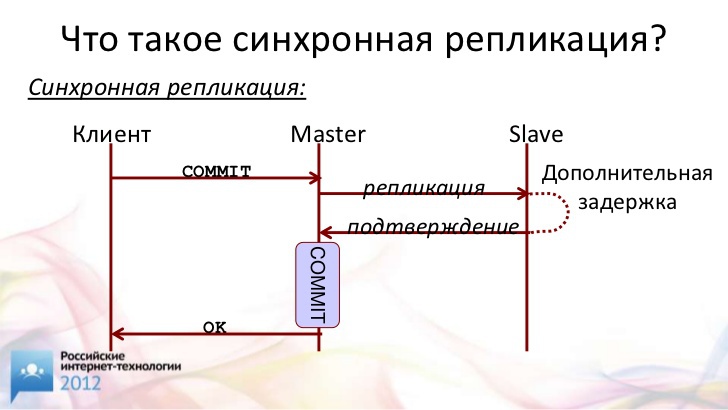
Мы получаем "commit" от клиента, отправляем данные транзакции на ведомый сервер. Ждем подтверждение от него. Только после этого "коммитим" и говорим клиенту "ОК". В этом случае, если ведущий сервер "упал", клиент знает, что с ним что-то случилось. Он пойдет на ведомый и проверит, закоммитилась транзакция или нет. Допустим, она закоммитилась, все хорошо.
Здесь у нас возникает некая задержка "общения" с ведомым сервером в момент выполнения операции "commit". Именно эта задержка является причиной представлений о том, что все будет крайне медленно.
Вот что пишут в Интернете по этой теме.

Попробуйте "погуглить" по запросу "synchronous replication"… Я это делал с аккаунта своей жены, потому что "Google" стал слишком умным и выдает мне совсем не то. Если какой-то человек захочет "с нуля" узнать что-то о синхронной репликации, то "Google" в первую очередь выдаст ему эти десять ссылок. Я их пометил особым образом.
"W" – это ссылка на "Википедию". Буквами "P" обозначены ссылки на синхронную репликацию в PostgreSQL. Буквами "M" – на полусинхронную репликацию в MySQL. "G" – это какая-то ссылка на "Google". Красными цифрами пронумерованы четыре ссылки на информационные ресурсы собственно о том, что такое синхронная репликация. По ссылке номер один мы получим следующую информацию: да, синхронная репликация защищает данные, но не применима в глобальных сетях.
Вторая ссылка дает нам точную границу – 300 километров, ни больше, ни меньше.
По ссылке номер четыре мы узнаем, что для использования синхронной репликации требуется очень дорогое высокопроизводительное оборудование, программное обеспечение (а кому не нужно высокопроизводительное программное обеспечение, интересно?) и очень дорогие каналы связи.
Ссылка номер три – это вообще "апофеоз" нападок на синхронную репликацию. Там доктор философии доказывает, что данные, на самом деле, гораздо лучше сохраняются при асинхронной репликации. Он это очень убедительно объясняет, и, собственно, сама статья называется "Правда о синхронной репликации".
Вот что мы получим, если просто "погуглим" на эту тему.
Откуда берутся такие "дикие" представления, мы сейчас посмотрим.
Что значит "синхронная"?

У нас была еще ссылка на "Википедию", помните? В "Википедии" декларируется принципиальное различие между синхронной и полусинхронной репликацией. Синхронная репликация, по мнению "Википедии" – это ситуация, когда мы не просто отправляем какой-то буфер с данными на ведомый сервер, но еще и ждем, пока он его подготовит, применит, запишет на диск, и только после этого пошлет нам "окей". Только после этого мы отвечаем клиенту.
Существует еще и полусинхронная репликация, – например, в MySQL. Когда мы просто копируем буфер на ведомый сервер, он шлет нам "ОК", проверяет контрольную сумму. Все хорошо, мы забываем о ведомом сервере и говорим "окей" клиенту.
Может показаться, что это принципиальная разница. Мало ли, вдруг ведомый сервер принял наш пакет, а потом на нем что-то случилось – и все, он эту транзакцию не закоммитил. Что делать?
А на самом деле все сводится к тому, останавливаем мы работу ведущего сервера из-за того, что на ведомом произошел сбой, или нет. Работу ведущего сервера мы не останавливаем. Мы завели ведомый сервер не для того, чтобы останавливать ведущий, если на ведомом что-то произошло. Если там что-то произошло, мы "гасим" ведомый сервер, перезапускаем его, ресинхронизуем и так далее. Ведомый сервер предназначен вот для чего: если что-то произойдет с ведущим, то мы пойдем на ведомый и будем использовать его базу.
Поэтому с точки зрения надежности хранения данных на практике нет никакой разницы между синхронной и полусинхронной репликацией. Нас на самом деле не волнует, что происходит с ведомым сервером. Если мы хотим большей надежности, мы устанавливаем больше ведомых серверов.
Вообще для любой распределенной системы справедливо следующее утверждение: чем больше в ней сущностей, тем выше вероятность того, что на какой-то из этих сущностей произойдет сбой. Как борются против таких вещей? Увеличением числа сущностей. Таким образом, вы живете с кластером. Думаю, что на "Amazon", например, каждую минуту происходят сбои, "вылетают" диски и блоки питания. Они все время это чинят. Мы выживаем просто за счет общего количества машин.
Таким образом, мы делаем вывод о том, что полусинхронная репликация – это то, что нам нужно.

Нам не нужно этих двухфазных коммитов… Классическая академическая теория относительно того, как это должно происходить, в ходу еще с 1960-х годов. Но практика показывает, что она не вполне жизненная. Я дальше покажу, что у нас получится, если мы откажемся от этих академических представлений.
Соответственно, асинхронная репликация у нас сводится к тому же самому, что и синхронная. Мы копируем буфер данных на ведомый сервер и все. В принципе, требования к "железу", программе, каналу точно такие же. Если у вас слишком медленный ведомый сервер, то, независимо от того, синхронная или асинхронная репликация, у вас возникнет недостаток ресурсов ведомого сервера. В конце концов, она станет бессмысленной.

Если у нас слишком узкий канал, мы будем просто не в состоянии послать все данные на ведомый сервер. В данном случае он сам будет "тормозить". Поэтому вся разница, которая у нас есть, состоит в том, что при синхронной репликации существует задержка, которая равна времени отклика другой системы.

Мы сейчас в первом приближении рассмотрели, что такое синхронная репликация, и поняли, что она не так уж страшна и не требует никаких особенных ресурсов по сравнению с асинхронной репликацией.

На этом все и заканчивается (не мой доклад). Что весь смысл введения понятия "синхронная репликация" – это все было придумано для того, чтобы защитить данные от потери. Для приложений, которые критичны к потере данных.

Мы никогда не задумывались о том, как наша библиотека будет работать в глобальных сетях. Реальность вносит свои коррективы. В данном случае эти коррективы оказались приятной неожиданностью.
Допустим, у нас есть некая база данных. Например, "Ebay". Там товары, пользователи, и так далее. Как мы получаем доступ к "Ebay" в Интернете.
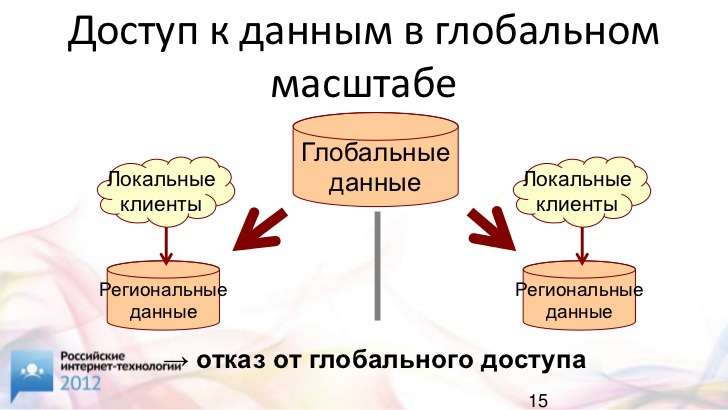
У нас есть глобальные данные. Что мы с ними делаем? Мы их просто "рубим" на региональные. Поэтому немецкие покупатели ходят на немецкий "Ebay", английские – на английский "Ebay". У нас Интернет, но, на самом деле, каждый региональный сегмент живет своей отдельной жизнью. Это, конечно, связано с тем, что доступ к какому-то центральному серверу был бы очень медленным.
Когда у нас получается разделить данные по регионам – это, конечно, очень хорошо. Это самый правильный способ решения таких задач. Скажем, товары и услуги обычно "привязаны" к региону.

Если у нас разделение данных по какой-то причине невозможно или нежелательно, нам приходится где-то иметь центральную базу. В ней, конечно, реализованы резервные копии и так далее, но находится она в конкретном дата-центре. С другого конца планеты придется "лезть" к ней через все эти сети.
Синхронный мультимастер
Вот тут у нас появляется синхронный мультимастер. Чем синхронный мультимастер лучше асинхронного?
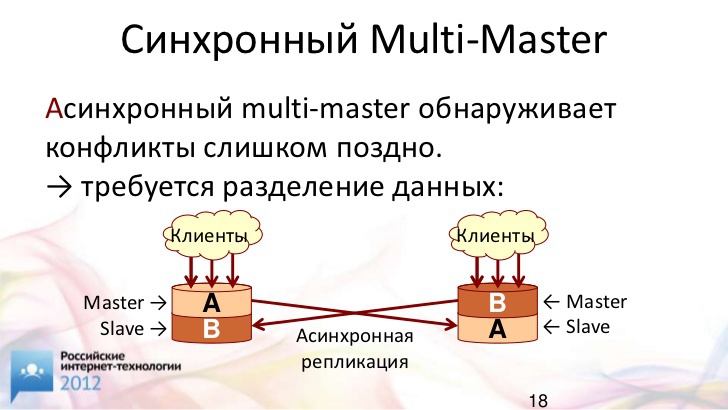
То, что в мире MySQL принято понимать под мультимастером (МММ) – это, на самом деле, никакой не мультимастер. Это просто суперпозиция схемы "ведущий-ведомый". Наши данные точно также делятся, и отдельный раздел модифицируется только на одном сервере, который является для него ведущим.
Мы уже выяснили, что мы не хотим разделять данные, – мы хотим иметь их все вместе. Поэтому мы не можем применять асинхронный мультимастер, потому что будем не в состоянии вовремя найти конфликт и исправить его до ответа клиенту.
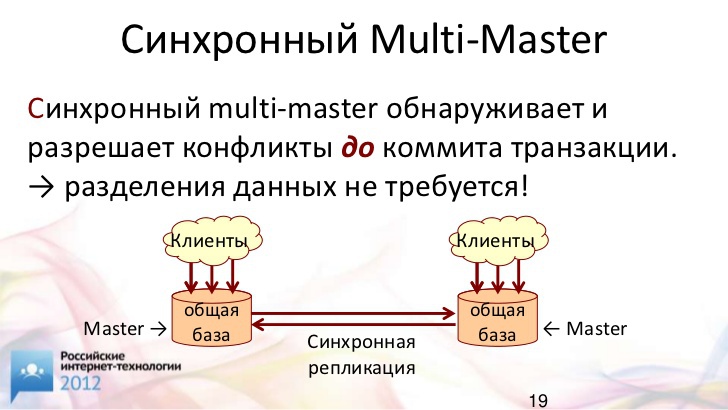
Когда у нас применяется синхронный мультимастер, у нас на серверах всегда есть актуальные данные о том, что происходит. Мы всегда можем вовремя обнаружить конфликт и вовремя его разрешить. Таким образом, мы можем модифицировать данные, находящиеся в одной таблице, даже в одной и той же строке на разнесенных серверах.
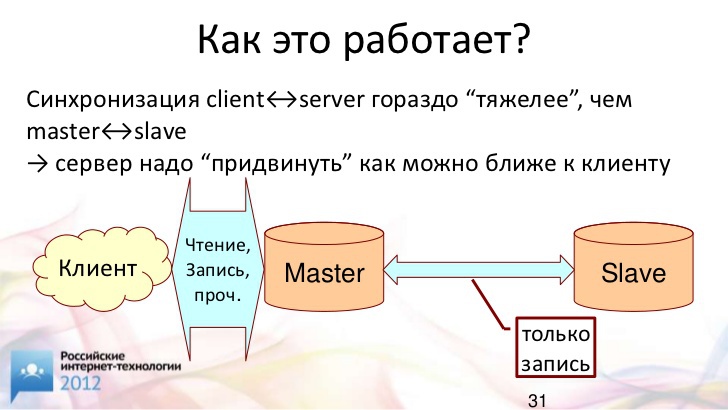
С помощью такой штуки мы можем попытаться "приблизить" серверы к клиентам. Что это означает? У нас будет глобальный мультимастер и синхронная репликация между этими серверами. Как это повлияет на скорость доступа клиентов к данным?
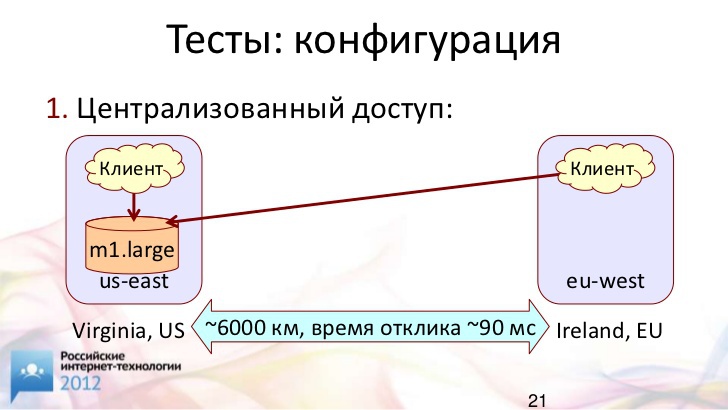
Специально для этого доклада я протестировал два таких сценария.
Первый сценарий. У нас есть некая база данных в Америке, например. У нас есть клиент в Америке и есть клиент в Европе. Они пытаются получить доступ к этой центральной базе данных. Расстояние между дата-центрами составляет примерно 6 тысяч километров, а время отклика по ping – около 90 миллисекунд. Это многовато, потому что теоретически скорость света ограничивает нас 40 миллисекундами. В принципе, мы можем ожидать, что при реально хорошей ссылке можно уложиться в 60 миллисекунд. Пока у нас 90 миллисекунд.
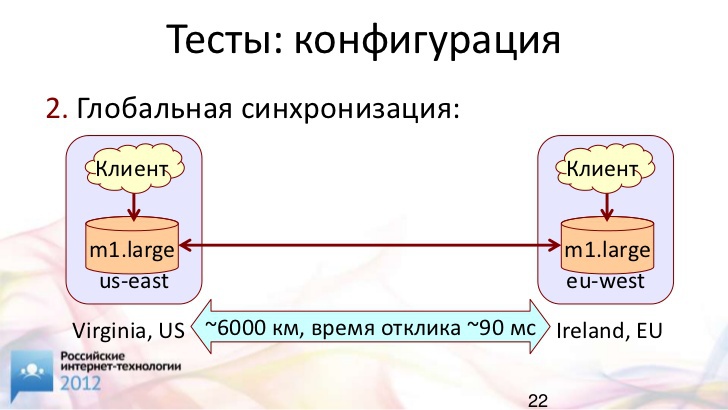
Вот второй сценарий, когда мы разносим серверы по дата-центрам поближе к клиентам. Соответственно, каждый из клиентов получает доступ к базе данных локально.

В качестве клиента я использовал "Sysbench". Это пример приложения, которое не поддерживает разделение данных. Там одна таблица, и все пользователи туда обращаются. Она дает хорошую статистику: время средней задержки (среднее время исполнения транзакции), 95 % граница времени исполнения транзакции, общая производительность транзакции в секунду.
То же самое было протестировано в двух режимах. Это умеренная нагрузка 8 клиентов (режим, в котором следует использовать сервер), когда у нас есть некий запас по производительности. Высокая нагрузка – тут я просто взял 64 клиента, чтобы "выжать максимум" из сервера. Естественно, никто в таком режиме не работает. Это было нужно просто для демонстрации общей производительности системы.
Вот что у нас получилось при умеренной нагрузке.
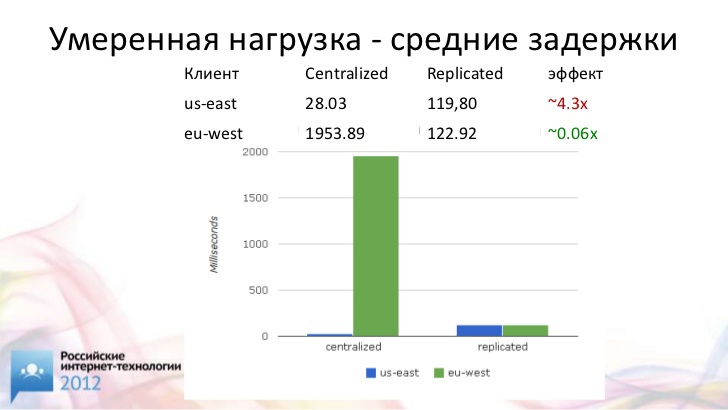
Посмотрим на среднее время исполнения транзакции. Мы видим, что у американского клиента везде все хорошо. Он получает доступ к базе данных локально. У него время исполнения транзакции равно 30 миллисекундам. Зато у европейского клиента время исполнения транзакции – целых 2 секунды. Я подозреваю, что никто даже не будет пытаться глобально работать с базой данных при таких задержках. Я понимаю, что бывают очень тяжелые транзакции, на несколько часов. Но здесь, когда у нас разница почти в два порядка, это практически нерабочий вариант.
Мы используем синхронный мультимастер и таким образом обращаемся на серверы, расположенные поближе к клиентам. Что у нас происходит? Американскому клиенту от этого внезапно стало хуже. У него в четыре раза выросло время исполнения транзакции. Зато у европейского клиента время исполнения транзакции уменьшилось в 16 раз.
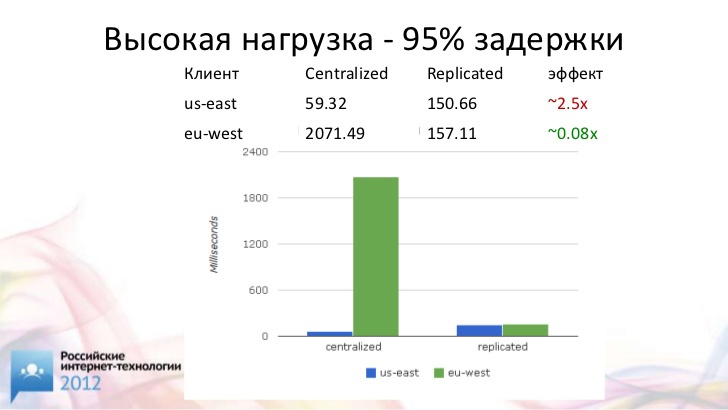
Если мы посмотрим на 95 % границу времени исполнения транзакции, то разница между доступом к локальному серверу и доступом к синхронизованному кластеру становится еще меньше. У американского клиента время исполнения транзакции вырастает всего в два с половиной раза, а выгода на европейском клиенте – порядка 12 раз.
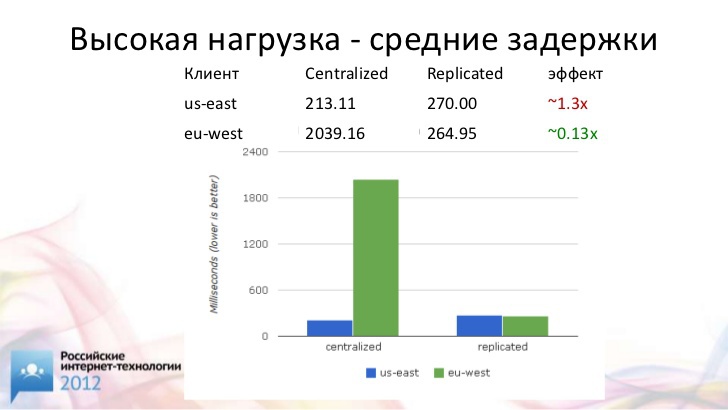
Когда мы используем базу в режиме высокой нагрузки (когда задержки становятся значительными по сравнению с задержками репликации), то вообще перестаем замечать существование синхронной репликации между двумя узлами.
Вот тут, например, у нас даже близко нет этих 90 миллисекунд времени отклика, который теоретически должен быть.
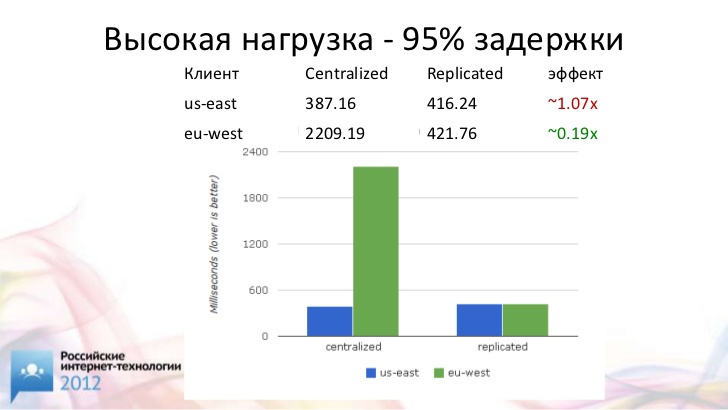
Что касается производительности, вот еще один пример. Если у нас есть один центральный сервер, его производительность будет в полтора раза ниже, чем у схемы, где применяется синхронный мультимастер. Это довольно неплохой прирост производительности.
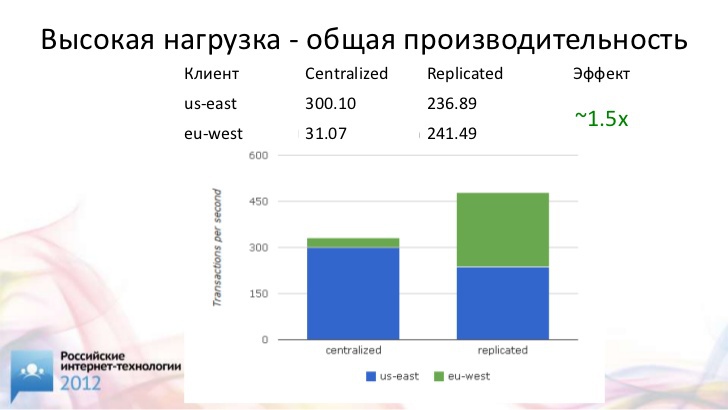
В данном случае мы получили не только более выгодное время исполнения транзакции, но и более высокую производительность. Это довольно искусственный пример. Никто не должен доводить свою базу до такой нагрузки. Вы теряете клиентов, если не можете обрабатывать запросы так быстро, как они к вам приходят. Тем не менее, я продемонстрировал, насколько "страшны" задержки синхронизации на самом деле.
За счет чего это происходит? У нас есть один очень важный и неизбежный источник синхронизации. Это непосредственно общение между клиентом и сервером. Нам от этого никуда не деться.
Клиент-серверный протокол, по определению, синхронный. Он гораздо "тяжелее", чем репликационный протокол. Клиент-серверный протокол включает в себя передачу массы данных туда-сюда. В репликации нам нужно просто отослать изменения, которые мы сделали в базе данных. Результаты селектов и все прочее сюда не попадают. Поэтому и получаем такую выгоду (поскольку у нас репликация гораздо тоньше и менее требовательна к сети, чем клиент-серверный протокол). Имеет смысл "подвинуть" ведущий сервер гораздо ближе к клиенту.
Эти результаты были получены с помощью MySQL и нашей репликационной библиотеки. Эти результаты применимы к любому хранилищу данных просто за счет синхронной репликации, которая теоретически является "тяжелой" и нужна только когда вам нужно защитить ваши данные. Вы можете реально улучшить скорость доступа клиента к данным.
Тем не менее, у нас есть издержки синхронизации. Мы видели, что для локального американского клиента среднее время исполнения транзакции выросло в четыре раза.

Как бороться с задержками?
Что мы можем противопоставить этим задержкам, от которых никуда не деться? То же самое, что мы делаем с задержками, которые происходят где-либо еще. Задержки синхронизации ничуть не отличаются от задержек доступа к диску или памяти.
Что мы делаем, когда нужно записать что-нибудь на диск? Буферизуем эти записи. В данном случае аналогом будет увеличение длины транзакции. Нам всем постоянно советуют делать транзакции покороче. Для локальных сетей это, возможно, правда. А здесь, если мы будем делать транзакции подлиннее, то сможем избежать излишней синхронизации между серверами и делать большую часть работы непосредственно с локальным сервером.
Второй вариант – это то, что случилось уже давно, а частоты процессоров не растут. Любое приложение, так или иначе, должно быть "распараллелено". Это не вопрос. В данном случае, пока у нас идет репликация одной транзакции, мы можем исполнять другую транзакцию. Мы просто повышаем количество одновременных клиентов в базе и таким образом решаем проблему общей производительности. Каждый отдельный клиент будет видеть эту большую задержку исполнения транзакции. Но, в общем и целом, мы будем в состоянии обработать практически такое же количество транзакций, как при доступе к одиночному локальному серверу.
Для интересующихся даю ссылку на ресурс, где можно загрузить программное обеспечение, которое использовалось в этом тесте.

Спасибо вам за внимание. Вопросы.
Вопросы и ответы
Реплика из зала: Как потом включить обратно в работу ведущий сервер, если он выйдет из строя? Он может быть включен обратно в работу, у него получится догнать репликацию?
Алексей Юрченко: Простите. Вы не могли бы повторить вопрос еще раз. Я плохо расслышал.
Реплика из зала: Допустим, у нас останавливается ведущий серверв. Ведомый включается в работу и работает какое-то время. Сможем ли мы потом опять включить в работу ведущий сервер, догонит ли он репликацию, или это невозможно?
Алексей Юрченко: Если мы говорим конкретно о наших разработках – да. Но это уже вопрос к тому, как вообще реализована репликация. Мы знаем, что в стандартной репликации MySQL этот процесс довольно сложен из-за отсутствия глобальных идентификаторов транзкций. Но это вопрос того, как вы сделаете ПО. Спасибо!























































