
Welcome to Write-Ahead Log (PostgreSQL's Write-Ahead Log)

Хейки Олави Линнакангас (Heikki Olavi Linnakangas): Здравствуйте! Меня зовут Хейки Линнакангас. Я работаю с PostgreSQL уже несколько лет. Мы занимаемся проблемами совместимости разных вещей с Oracle. Сегодня мы поговорим о PostgreSQL WAL – журнале регистрации записи с упреждением.
PostgreSQL – очень традиционная SQL-СУБД. Ее разработали в университете Беркли в 1995 году. Она очень быстро была лицензирована, сейчас ее широко распространяют. Лицензию вы можете получить легко.
Она очень гибкая, конечно. Вы можете написать все: все типы, все функции можно ввести туда.
PostgreSQL – достаточно стабильная традиционная база данных SQL. Я хочу рассказать о регистрации записей с упреждением в PostgreSQL.
По сути, все базы данных используются для транзакций и для совместимости. Это очень важно. Это центральное звено нашей технологии базы данных: используется система файлов в журнале обновлений.
В чем идея? Вы производите обновление в базе данных. Прежде всего, вы вводите запись обновления, модифицируете эту страницу. Вы делаете запись на диск, прежде чем обратиться к базе данных.

Мы знаем, что регистрация записи с упреждением также известна, как журнал транзакций или журнал обновлений. Практически в каждой СУБД есть такой журнал. Он иногда называется "журнал обновлений" или "журнал транзакций". Если вы сделаете выбор инструмента, то также увидите, что там имеется журнал записей.

Как это работает? Когда вы говорите о концепции, вы говорите о последовательности. Для каждого изменения делается одна записть. Вы пишете что-то, обновляете – вы говорите, что именно вы собираетесь сделать: обновить запись либо вычеркнуть, уничтожить. Тогда вы задаете эту функцию в записи: что вы хотите сделать, какова ваша цель.

В PostgreSQL эта функция была введена в версии 7.1. Она была написана Вадимом Макеевым в 2001 году. Он из России, это очень активный разработчик PostgreSQL. Он учитывал все функции, как и журнал транзакций. Он описал очень много индексов, в том числе для загрузки.
В PostgreSQL, что интересно, у вас есть только журнал обновлений. Это означает, что если вы что-то уничтожаете, вы находитесь в этом статусе до крэша. Например, если вы делаете какие-то изменения, что-то вносите в базу данных и хотите осуществить возврат, "откат" – вы создаете запись по возвращению. Это великолепное свойство для записи обновлений.
Несколько лет назад я использовал Microsoft SQL. Я делал огромную транзакцию, которая проходила полтора часа. Было очень много разных маленьких отчетов. Что-то там было не так с транзакцией. В течение всей этой длинной транзакции приходилось часто вызывать обратные функции, делать откат. Все это требовало большого времени.
Теперь у нас в PostgreSQL нет этой проблемы, она была решена благодаря функции "root back". Если вы применяете ее в PostgreSQL, реакция происходит мгновенно, и функция становится видимой. Можно "уничтожить мусор", то есть то, что вам не нужно и от чего можно избавиться.
Что еще используется? Нет ограничений для транзакций. Нет ограничений по размеру транзакции – не имеет значения, насколько она большая. Мы можем также выполнять операции проверки. На определенных этапах мы можем проверять, каким образом происходит транзакция, открылась ли она, и до сих пор ли она проходит. Возможно, вы не хотите этого делать… Но постоянно открытая транзакция – это не очень хорошая идея. Это несет угрозу другим данным в базе.

Здесь есть пример. Он сделан для очень простого отчета, для ведения журнала транзакции. Прежде сего, вы вводите Heap, который сам по себе записывается в таблице. Затем у вас есть индекс в дереве Btree. Если у вас система с двумя индексами, это проявляется здесь.
Дальше идет маршрут изменения. По сути, это автоматически происходит. Вы просто записываете эти данные. Вы можете видеть, каким образом индекс разбивается по страницам. Вот таким образом это происходит.
Наконец, есть последняя запись по совершению транзакции с указанием времени. Затем идет то, что уже сделано. Есть сброс – те запросы данных, где идет контроль кэша.
У вас также есть период задержки, но он небольшой. Нужно все-таки еще работать над решением проблемы с задержкой.
Что вам нужно? Только одно: сбрасывать эти данные на диски. Это не страница базы данных, которая имеет отношение к журналу транзакций. Это все очень быстро происходит, это очень хорошо реализовано в PostgreSQL.
В журнале обновления есть два момента относительно работы с данными. Вы вписываете индексы и вносите те же изменения в журнал обновления, журнал транзакций. Это гораздо быстрее делать последовательно.
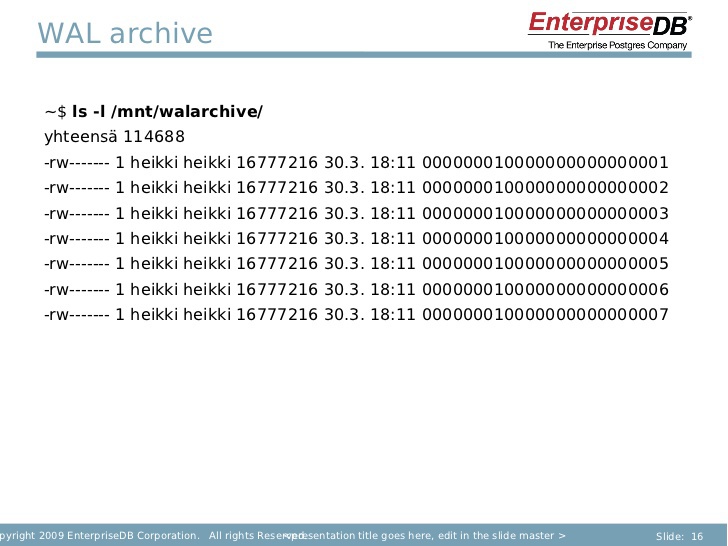
Также здесь есть обновления в системе файлов, которые делятся на два сегмента. 60 мегабайт внутри, вы видите директории. Когда вы работаете, вы видите, что появляется все больше файлов.

Есть пограничный момент, где можно проверить, какие файлы идут. Названия файлов очень интересны: они идут последовательно. Но иногда происходят перебои – это очень забавно выглядит. Прежде всего, идут цифры – цифра 1. Если вы делаете это в течение какого-то времени, вы видите в основном последовательную организацию записей.

Также стоит упомнуть про инструменты, которые были разработаны недавно. Те примеры, которые я вам здесь представил, касаются функций отработки и настройки. Вы можете отразить эту опцию (WAL_DEBUG compile option), чтобы отработать версию конфигурации. Это очень хорошая разработка – видно, каким образом работает вся система. Вы можете загрузить все файлы и посмотреть, каким образом они работают. Достаточно продуктивно, по-моему.

Очень важная часть работы журнала транзакций – сброс файла на диск до того, как будут произведены какие-то изменения для страниц данных. Вы можете отслеживать Btree-страницу, смотрет, что и как в действительности происходит.
Мы видим, что произошли изменения, до того, как запись транзакции была сделана. Их нужно отразить в журнале транзакций. В случае сбоя WAL "переигрывается", чтобы воспроизвести несохраненные изменения.
Например, мы можем использовать право копирования FCK. Если у вас произошел сбой, вы можете увидеть все ошибки и исправить их. Но журнал транзакций здесь играет основную роль. Здесь есть специальные индексы и механизм индексирования, который позволяет видеть все, что происходит.
"Начинка" здесь совершенно другая, в отличие от права копирования, которое всем известно. Это очень простой способ сделать индексы и реализовать эти функции.

В случае сбоя, вы начнете восстанавливаться с последней контрольной точки. Вы увидите много изменений. Вы можете иметь сотни разных файлов с нарушенной структурой.
Вы можете отсечь их. Для этого у нас существуют контрольные точки. Они позволяют нам отсекать все сбои, все файлы, которые были повреждены.
Когда вы проводите контрольный замер, в буфере обмена происходит запись. Вам не нужно беспокоиться, потому что контрольные точки создаются автоматически. Есть также команды, которые можно использовать для выставления контрольных точек вручную, если почему-то не сработает автоматическая функция.

Иметь журнал транзакций нужно для того, чтобы избежать последствий сбоя или максимально обезопасить свою платформу. Это очень важно: вы сохраняете тот же порядок. В PostgreSQL это происходит очень стабильно. В случае сбоя используется механизм защиты от сбоев.
Однако было бы очень плохо, если бы имелся некий индекс, указывающий на отчет, который не существует. Транзакции выполняются последовательно, чтобы избежать всех этих проблем. Если и происходят какие-то изменения, они вносятся в таблицу. Это также решает проблему с разбиением страницы индекса.
Таким образом, мы можем использовать бустерный порядок, чтобы использовать нечто вроде инструкции, и реорганизовать файлы в нужном порядке. Это самое лучшее, что здесь можно сделать.

Итак, резюме всего вышесказанного.
Мы можем подвести итог тому, о чем говорили в этой части презентации. Регистрация записей в журнале WAL очень пригождается в том случае, если происходит какой-то сбой, если что-то случается с базой данных. Все это находится под контролем.
Индекс может указывать на то, чего не существует. Этого можно избежать. Если индекс имеющейся страницы 50/50, транзакция сможет этого избежать.

В рамках журнала транзакций вы можете использовать и другие функции. Что они позволяют сделать? Это резервное копирование онлайн. Для нас неприемлемо блокировать, "закрывать" какие-то данные. Транзакция будет продолжаться, и мы совершим необходимое "оперативное вмешательство".
Вы видите все возможности, все черты, которые важны. Транзакция проходит благодаря журналу обновлений транзакций.

Еще вы можете использовать продвинутые возможности архивизации, создания архивов. До этого я говорил: когда вы делаете проверку и отсекаете все поврежденное, чтобы сохранять соответствие с проходящей операцией, стоит применить архивы.

PostgreSQL очень гибко действует по отношению к архивам. Есть команда conf file и команда архива, которая задается для каждого файла WAL. Будет вызываться команда, которая будет выполнять "cp %p", либо она может задавать характеристики, которые здесь представлены.
Когда вы запускаете сервер, то можете копировать файлы WAL в архив. Это нужно выполнить самим – задачу отсечения сбоев.
Это вы можете делать сами. Как вы видите, это можно реализовать очень быстро.

В отношении резервирования это обычно перекрывается базой данных. В это время вы можете задействовать резервирование и использовать для копирования снимок состояния. Если вы сможете это сделать, это очень вам поможет. Но обычно снимок делается в файловой системе, что очень сложно. WAL-архив позволяет делать это, необходимая функция осуществляется.

Как это работает? Вы начинаете создание резервной копии базы данных с команды SELECT pg_start_backup(). После того, как вы это сделали, определяете ту команду, которая вам нужна. Вы выполняете rsync/tar/что угодно. Когда вы это сделаете, то используете команду стоп, чтобы выполнить резервирование.
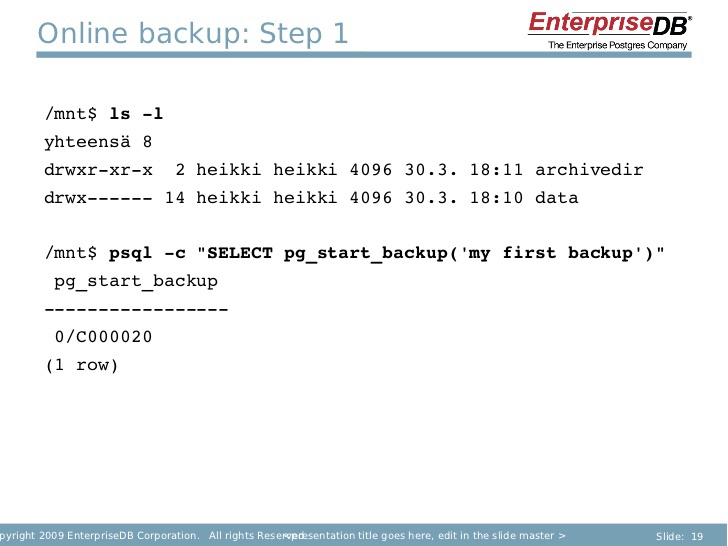
Первый шаг, действительно, позволяет создать резервную копию. Затем вы используете эту команду, чтобы копировать данные из директории.

Как вы видите, здесь 40 мегабайт – это не такая уж большая база данных. В базе могут быть терабайты данных – она может достигать очень больших размеров. Можно в течение целого дня вести эту транзакцию, независимо от размеров. Но в этом случае все происходит очень медленно.
Специально так сделано, чтобы функция не задействовала всю систему. Тогда ее выполнение не приведет к сбою всей системы. Я говорю о том, что вы выполняете в рамках резервного копирования.

Система сообщает вам, что все сегменты заархивированы.

После того, как вы это сделали, остется последнее действие: нужно скопировать все файлы из архива WAL в резервную копию. Можно поместить их в тот же файл или в другой файл. Эти два файла вместе обеспечат вам достаточно надежное резервирование.

Еще одна интересная функция – восстановление на определенный момент времени. Кто из вас это делал в "живой" базе данных? Были же ситуации, когда стиралась таблица или информация из таблицы, а потом вы забывали все восстановить? В случае такого сбоя очень помогает функция восстановления базы на определенный момент времени.

Если у вас реализовано собственное онлайн-резервирование и есть возможности WAL, можно восстановить данные на любой момент времени, который нужен. Если в течение недели вы ведете WAL-архив, на любой момент из этого периода можно будет "заказать" такое восстановление. Можно выбрать момент прямо перед тем, как вы случайно все стерли из таблицы.
Если вы хотите восстановить базу данных, то обращаетесь к резервному файлу, резервному архиву. Вы видите, какие записи надо сделать. Вы формируете команду recovery.conf формируете. Далее вы видите, какие команды надо написать.
По умолчанию восстановление будет идти до конца записи журнала WAL. Если вы хотите, чтобы процесс остановился раньше (в какой-то момент времени), вы должны указать это как цель восстановления. Это очень удобный инструмент.

Еще одна продвинутая функция – репликация. PostgreSQL может производить репликацию, когда у вас есть архив WAL и используются резервные серверы. Можно передавать WAL, по мере его генерирования, на резервный сервер, и будет производиться репликация. Либо можно осуществлять прямую потоковую передачу с сервера по TCP в ходе этого процесса. Резервный сервер может использоваться только для запросов на чтение.
Когда у вас есть ведущий (англ. master) и ведомый (англ. slave) серверы, можно всю копию базы данных ведущего сервера перенести как резервную на ведомый сервер или вызвать уже имеющуюся копию с ведомого сервера. Репликация – очень удобный инструмент. Можно пользоваться им в файловой системе. Можно иметь сколько угодно ведомых серверов, использовать ту или иную систему – вы можете хранить файлы, как вам удобно.

Есть ли какие-то вопросы относительно транзакций с журнальными записями или вообще системы WAL?
Вопросы и ответы
Реплика из зала: По какой причине вы ждали так долго и добавили репликацию только в версии 9.1? У вас уже два года назад была эта технология. Почему вы медлили с релизом? В самой первой версии у вас были такие инструменты.
Хейки Линнакангас: В самом начале Write-Ahead Log (WAL) это существовало только как задумка. Сейчас это более продвинутая функция. Формат WAL позволяет проводить онлайн-репликацию записей в журнале, но все-таки здесь есть сложности с выполнением этого на ведомых серверах.
Мы работали над этим. Это уже шаг вперед по сравнению с простым журналом транзакций. Это продвинутая функция. Репликация присутствует начиная с версий 8.1, 8.2. Но это новый вариант репликации. Я думаю, ответ на ваш вопрос заключается в том, что отдельно это не казалось достаточно значимым, а сейчас мы это сделали.
Реплика из зала: Я не понял, WAL хранит снимки данных или утверждения о манипулировании данными?
Хейки Линнакангас: Снимки в онлайн-резервировании – вы это имеете ввиду?
Реплика из зала: Нет. Я говорю о хранении в WAL-журналах. Что хранится: заявления о модификации (команды о модификации) страниц или снимки?
Хейки Линнакангас: Мы физически модифицируем журнал, а не внесенные записи или утверждения. Давайте посмотрим: здесь у нас запись, но мы ее саму не меняем. Мы выполняем какие-то действия с журналом.
Реплика из зала: Данные вы не изменяете – это модификация низкого уровня. Вы используете резервирование WAL, но в вашем примере это очень специфично. Где вы будете хранить данные, которые были утеряны или сброшены? Вы показывали пример со стертыми записями и говорили о возможностях резервирования WAL. Когда какие-то данные стираются в таблице, где они хранятся, если они не хранятся в WAL?
Хейки Линнакангас: Что мы делаем, если стираем, например, какие-то строки и потом хотим их вернуть – такой у вас вопрос? Когда мы стираем что-то, мы отмечаем, что данные стерты. Сами данные физически сохраняются. Есть только запись о транзакции "убрать данные".
Реплика из зала: Если создается вакуум, и он начинает работать, данные уже восстановить нельзя.
Хейки Линнакангас: Да, после формирования вакуума. Но когда вы стираете данные, они сначала просто делаются невидимыми. Они еще хранятся, их можно восстановить.
Здесь архитектура, которая отличается от ряда других баз данных. Нам необходимо будет лишь отметить стертые строки. Например, пометить, что нужен возврат к старой версии. Либо отметить новую версию как новую, старую как старую – тогда обе они будут сохранены в системе хранения. Но вы должны будете потом определиться, что вам нужно.
Реплика из зала: Все-таки меня вот что интересует: если вакуум начинает функционировать в таблице, вы уже не можете восстановить данные, используя резервирование WAL. Можно или нет восстановить эти данные?
Хейки Линнакангас: Вы спрашиваете, можно ли восстановить данные, когда вакуум уже запущен или после того, как он сработал?
Реплика из зала: Да. Вы говорили, что можно использовать резервирование WAL, и можно произвести восстановление данных на какой-то момент времени.
Хейки Линнакангас: Идея восстановления данных на какой-то момент времени заключается в том, что вы начинаете с полного резервирования. Сначала вы проводите полное резервирование, а потом уже воспроизводите журнал заново до того момента времени, который определили. У вас должны иметься все сохраненные данные. Если вы что-то переписали или что-то удалили, и там уже сработал вакуум, конечно, это восстановить нельзя.
Реплика из зала: Большое спасибо за вашу презентацию. Я не слишком хорошо знаком с PostgreSQL. Это распределенная система? Можно ли в ней масштабировать горизонтально?
Хейки Линнакангас: Это не распределенная система. Можно сделать репликацию по схеме "ведущий-ведомый", и есть целый ряд проектов, которые проводят такие репликации поверх PostgreSQL, но сама эта система не распределенная.
Реплика из зала: Как физически хранится информация?
Хейки Линнакангас: В виде файлов, файловой системы.
Реплика из зала: По узлам. Один узел на один экземпляр PostgreSQL. Да?
Хейки Линнакангас: Это зависит от того, зачем вы делаете репликацию. Если репликация основана на одном типе журнальных записей, опирающихся на ведомые серверы, тогда информация с них и будет воспроизводиться. Есть триггерные системы, которые реплицируют транзакции на разные узлы.
Реплика из зала: Как производительность в таких продуктах зависит от интенсивности нагрузки? Есть ли технология резервирования некоторых баз данных, а не всех?
Хейки Линнакангас: Нет. Здесь либо все, либо ничего. Можно делать частичное резервирование в триггерных программах. Но здесь вы должны всю базу данных резервировать, а потом можно будет с этим работать.
Реплика из зала: А какова производительность в варианте "ведущий-ведомый" при применении этой технологии? Например, насколько медленно будет проходить транзакция, и какая нагрузка будет применяться?
Хейки Линнакангас: Здесь нет прямой зависимости. Многое зависит от "железа". Это однопотоковый процесс. Если вы применяете проект "ведущий-ведомый", и если на уровне ведущего сервера у вас большое количество обновлений, может создаться очередь при передаче на ведомый. Но других ограничений нет.
Реплика из зала: Проекты на ближайшее будущее. Есть ли разработки по новым системам визуализации?
Хейки Линнакангас: Пока не знаю. Может быть, кто-то этим заинтересуется. Если здесь есть студенты, сейчас "Google" и другие компании заинтересованы в привлечении к разработкам инициативной молодежи.
Если вопросов больше нет, спасибо.























































